
What Are Precipitation Grids?
Minnesoata's Volunteer Observers Are the Backbone
Minnesota benefits from a unique network of over 1000 volunteer daily precipitation monitors that has been in place since the 1970s.
Often called "MnGage" or "HIDEN" (because of its high-spatial density), this network gives Minnesotans access to world-class
precipitation data. The State Climatology Office appreciates the outstanding service the volunteer observers provide.
Minnesota's preciptation monitoring system is a "network of networks," including volunteers from Soil & Water Conservation Districts, the National Weather Service "COOP" program, a DNR "backyard" observer program, and localized or short-term programs that have come and gone in Minnesota since the early 1970s. More recently, the national "CoCoRaHS" network has become the largest volunteer precipitation program in the US, and from 2020 to 2023, Minnesota has recruited significantly more new observers to this program than any other state.
Of course, not all observers have the same availability or interest in precipitation monitoring, leading to variations in the length and completeness of data at different locations. Volunteer observers are regular people who move, get sick, and experience life changes just like everyone else. Replacing one observer with a new volunteer can be difficult or even impossible, especially in sparsely populated areas. Thus, even in Minnesota's excellent network, we find observer stations with gaps, others that were terminated, and others still began somewhat recently. These data variations can pose challenges to anyone looking for a continuous data record (for example, 35 years of complete daily precipitation data).
Not only do we see variations in data completeness from one location to the next, but we also see variations in the density or coverage of observers across the state. These changes in observer coverage largely follow the patterns of population, but also refelct local needs for observers.
All of the variations in record lengths and observer coverage over time and across the state offer the solution to the problem of data-completeness, and a process known as "gridding" can be used to fill gaps in both space and time. Gridding uses equal-sized squares (or grid cells) over an area to gather information from every data point within each square or cell, and then uses mathematical techniques to relate cells within the grid to one-another. Virtually any smooth-looking, contoured map will have an underlying data grid. Gridding is, in essence, a "strength in numbers" approach to data: we use the abundance of exisiting data to help us understand what we may be missing between stations, and from a given observer record.
What the gridded precipitation data set will do for the researcher:
The gridded precipitation data frees the researcher from the following tasks:
- locating the nearest precipitation monitoring site to the point of interest
- filling gaps in the data record
- locating or calculating historical summary statistics (normal, 30th and 70th percentiles) for the point of interest
 How it works ... the precipitation data set:
How it works ... the precipitation data set:
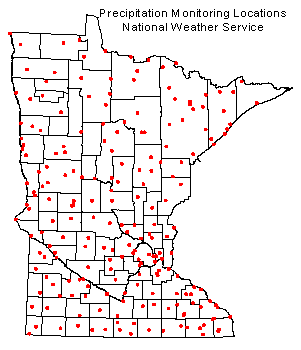
The gridded database is derived from a monthly precipitation database maintained by the State Climatology
Office. Through an act of Congress in 1890, the predecessor to the National Weather Service (NWS) was formed and
given the mandate (among other responsibilities) to monitor the climate of the United States. Because a network of
professionally staffed weather monitoring sites was economically impractical, the NWS established a network of
approximately 200 volunteer weather observers across Minnesota. These observers were well distributed geographically
(see map at right), and provided a reasonable depiction of the states climate conditions.
The network remains in place today and is the backbone for climate monitoring in Minnesota as well as in other states and territories.
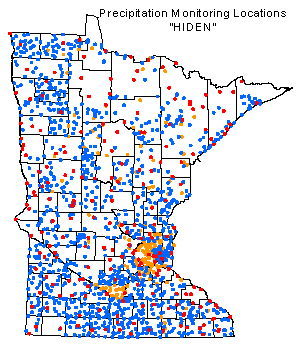 While the NWS network offers a large and invaluable data resource, it was long recognized that the spacing
between observers is too great to sufficiently describe precipitation patterns formed by isolated thunderstorm
activity. Recognizing this shortcoming in the NWS network,
farsighted individuals in the early 1970s formed Minnesotas High Spatial Density Precipitation Network (HIDEN).
This collaborative effort involves many water-sensitive agencies (most notably Soil and Water Conservation Districts), and
the combined result is a "network of networks" leading to a precipitation monitoring army of over 1400 volunteers
(see map at left).
While the NWS network offers a large and invaluable data resource, it was long recognized that the spacing
between observers is too great to sufficiently describe precipitation patterns formed by isolated thunderstorm
activity. Recognizing this shortcoming in the NWS network,
farsighted individuals in the early 1970s formed Minnesotas High Spatial Density Precipitation Network (HIDEN).
This collaborative effort involves many water-sensitive agencies (most notably Soil and Water Conservation Districts), and
the combined result is a "network of networks" leading to a precipitation monitoring army of over 1400 volunteers
(see map at left).
 How it works ... the data gridding process:
How it works ... the data gridding process:
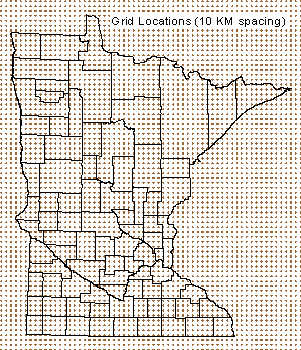
To overcome the problems a data gaps across space and time, the State Climatology Office prepares monthly
precipitation grids. Grids were prepared using the NWS data from 1891 to 1972. For the period 1973 to the present, the HIDEN data
(which includes NWS data) are used. For each month of each year, monthly precipitation totals are estimated for grid nodes at
regularly spaced (10 kilometers) intervals (see map at right). The estimates are derived using an
interpolation technique called "Kriging", which makes use of the irregularly spaced data in the vicinity of the node to assign
it a value. This way, all precipitation data provided by a volunteer observer, be it one month or one hundred months, are fully utilized
in the creation of a data time-series. A precipitation total is calculated for every grid node, for every month. There will never
be a missing value. Once the grids are created, the calculation of long-term summary statistics such as normals
and percentiles can be performed on each grid node.
Possible problems with the gridding process:
No interpolation scheme is without caveats. Some grid nodes are located in sparsely populated areas, or areas without a
well developed monitoring network. Obviously, interpolations are most accurate when an array of nearby data exists. The
gridding process also tends to "wash out" geographically isolated areas of high or low precipitation. Although the interpolation
technique gives greatest weight to the nearest data point, value assignment to a grid node representing an isolated area of
high or low precipitation will be influenced by other neighboring data points that may not reflect the small
area of dryness or wetness.
Advantages of gridded data for spatial analysis:
One of the advantages of a spatially-complete precipitation coverage is the ability to easily calculate
areal averages. By overlaying a boundary (for example, a watershed) upon the grid structure, a researcher can
query the values of all grid nodes found within the the polygon, and compute the area average.
Example
Conclusion:
Using these precipitation grids, researchers have access to a precipitation database that is continuous across
time and space. Applications using the gridded monthly precipitation database locate the grid nodes nearest to the user's point of
interest and present the time-series interpolated from those nodes. Although the synthetic data will somewhat lack in precision, the
database should provide a sound foundation for determining the general precipitation regime experienced at a particular
location and period of time.